
目次
1.OPTIMIZELY 統計エンジンとは何か、および他の統計モデルとの相違点について2.結果ページの統計
3.偽陽性率の制御
4.差異区間
5.統計的有意性と差の区間との関係
6.推定待ち時間と 0% の有意性
7.ビジネス上の意思決定のための統計エンジンの解釈
8.時間の経過に伴う統計的有意性の向上
9.外部イベントによる訂正
10.OPTIMIZELY での収益の処理
11.OPTIMIZELY では片側検定と両側検定のどちらが使用されますか?
12.実装
13.統計的有意性の設定
OPTIMIZELY 統計エンジンとは何か、および他の統計モデルとの相違点について
実験を実行すると、Optimizely は各バリエーションが目標に沿ってより多くのコンバージョンを達成する可能性を統計的に判別します。
なぜこの点が重要なのでしょうか?結果を確認するときには、ベースラインとバリエーションの比較よりも、バリエーションを今後実装した際に、ベースラインに比べバリエーションが実際に優れているかどうかを予測することに関心が集まる可能性があります。つまり、実験結果から効果を得られることを望みます。
Optimizely の統計エンジンは、統計的有意性の計算を強化します。統計エンジンは、実験担当者が統計的な厳密さをもってテストを実行できるようにしつつ、誰でも結果を解釈できるようにする目的で最適化された統計フレームワークを採用しています。具体的に言うと、統計エンジンを利用すれば、事前に設定されたサンプルサイズ、テストの目標の数やバリエーションの数に関係なく、テストの実行中に結果に基づいてビジネス上の意思決定を行うことができます。
あらゆる統計計算と同様、実際には何も発生していないのに実験では増加しているように見えるという可能性は常にあります。このため結果ページには、表示される結果に Optimizely の信頼度が表示されます。これにより、統計に関する専門家レベルの知識がなくても、結果に関するビジネス上の意思決定を行うことができます。
Optimizely は、このように強力でありながら容易に理解できる統計方法論を提供する初のプラットフォームです。その他の統計フレームワークが Optimizely ほど容易では
ない理由について、詳しく説明します。
結果ページの統計
統計的有意性
Optimizely では、各バリエーションで 100 件の訪問者と 25 件のコンバージョンを達成するまでは、勝者と敗者を宣言しません。また、Optimizely で結果が統計的に有意であると判断されるとその結果が表示されることがよくあります。どのようなことなのでしょうか。さらに詳しく説明します。
統計的有意性は、特定のバリエーションとベースラインとの間のコンバージョン率の差が偶然によるものではない尤度を表します。統計的有意水準は、リスク許容度と信頼水準を反映します。
たとえば、結果が 90% の有意水準で有意である場合は、確認できる結果が、偶然ではなく、実際に行われた変更によるものであることが 90% の信頼度であると言えます。
なぜこれが必要なのでしょうか。統計では母集団のサンプルを観測し、このサンプルを使用して合計母集団の根本的な行動を推論します。Optimizely ではこの観測を使用して、改善指標が計算されます。
観測した内容が実際の根本的な行動を反映していない可能性は常にあります。たとえば、80% の有意水準を設定し、優勢なバリエーションが観測される場合、観測した内容が実際には優勢なバリエーションではない確率が 20% あります。90% の有意水準では、誤差の確率が 10% に減少します。有意水準が高くなるほど、実験に必要な訪問者の数は増加します。Optimizely で表示できる最大有意水準は >99% です。これは、結果が 100% 有意であることは技術上不可能であるためです。
統計的有意性により、実験での偶然誤差率を制御できます。対照実験で発生する可能性がある 3 種類の結果を次に示します。
- 正確な結果:テストデータが正確な結果を示します。したがってオリジナルとバリエーションに差異がある場合にはデータは勝者を示し、差異がない場合にはデータは勝者を示しません。
- 偽陽性:テストデータでオリジナルとバリエーションの差異が示されるが、実際にはこれはデータのランダムノイズに過ぎず、オリジナルとバリエーションの間に差異はありません。
- 偽陰性:テストでオリジナルとバリエーションの差異が示されないが、実際にはバリエーションが勝者です。
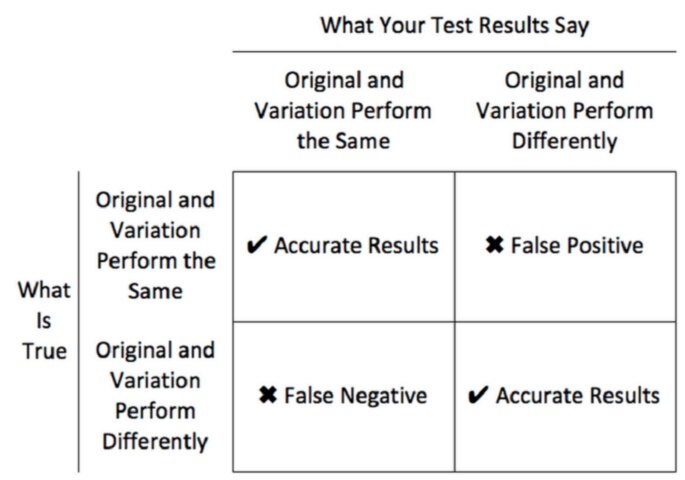
統計的有意性とは、観測値が誤検知ではなく、実際の根本的な行動を示している可能性の程度を示します。
デフォルトでは、有意性は 90% に設定されています。これは、観測結果が偶然によるものではなく実際のものである可能性が 90% であることを意味します。つまり、優勢または劣勢バリエーションを正しく宣言する可能性は 90% です。別の有意性しきい値を使用する場合は、Optimizely がプロジェクトの勝者または敗者を宣言する有意水準を設定できます。
有意水準が低い場合、誤差の尤度が上昇しますが、顧客はより多くの仮説をテストし、より迅速に繰り返すことができます。有意水準が高い場合、誤差の尤度が低下しますが、大きなサンプルが必要となります。
適切な有意水準を選択することで、実行するテストのタイプ、これらのテストで達成したい信頼度、および実際に受信するトラフィックの量のバランスをとることができます。
偽陽性率の制御
どのテストでも誤った宣言が行われる可能性があります。つまり、実際には 2 つのバリエーションの間で行動に根本的な差異がない場合に、決定的な結果が観測される可能性があります。特定のテストで誤差の尤度を 100 - [統計的有意性] として計算できます。つまり、統計的有意性の数値が高くなるほど、誤った宣言を行う確率が減少します。
従来の統計では、多数の目標とバリエーションを一度にテストすると、誤った宣言のリスクが高くなります(「多重比較」または「多重テスト問題」)。これが発生するのは、従来の統計が偽陽性率を制御することで誤差を制御しているためです。ただし、この誤差(有意性しきい値で設定)は、誤ったビジネス上の意思決定を行う確率とは 一致しません。次に、目標とバリエーションの追加に伴ってこのリスクがどのように上昇するかを示します。

Optimizely では、偽陽性率ではなく偽発見率を制御することで、誤差と偽陽性のリスクを制御します。誤差率は、偽発見率 = 誤った勝者宣言および敗者宣言の合計数 / 勝 者宣言および敗者宣言の合計数として定義されます。
重要:
実験開始後の目標またはバリエーションの追加は推奨されません。早期の時点ではこの影響は見られませんが、トラフィック量の増加に伴い、新しい目標またはバリエーションの追加が既存の結果に影響する可能性が高くなります。
注:
Optimizely では、第 1 目標として選択した目標が偽発見率制御の計算で特別に扱われ、常に統計上最優先されます。偽発見率制御により、複数の目標とバリエーションを実験に追加するときの「多重テスト問題」に対し、第 1 目標の整合性が維持されます。
差異区間
統計的有意性により、バリエーションがパフォーマンス基準より高いか低いかを、ある程度の信頼性で確認できます。差の区間では、オリジナルとバリエーション間の差異が実際に存在する値の範囲を確認できます。
差異区間は、特定のバリエーションを実装する際に予期できるコンバージョン率の信頼区間です。差異区間は、2 つのコンバージョン率の間の絶対差異の「許容誤差」と考えることができます。
バリエーションが統計的有意性に達すると、その差異区間全体が 0% より上(優勢なバリエーション)または 0% より下(劣勢なバリエーション)になります。
- 優勢なバリエーションの差異区間は、0% を完全に上回ります。
- 不確定なバリエーションの差異区間は、0% を含みます。
- 劣勢なバリエーションの差異区間は、0% を完全に下回ります。
Optimizely では、プロジェクトの統計的有意性しきい値を設定したレベルで、差異区間を設定します。このため、勝者を宣言する有意性として 90% を受け入れる場合は、その区間が正確であるという信頼性として 90% を受け入れることになります。
差の区間は、相対コンバージョン率ではなく絶対コンバージョン率を表すことに注意してください。そのため、基準コンバージョン率が 10% でバリエーションのコンバージョン率が 11% であった場合は、次のようになります。
- コンバージョン率の絶対差異は 1% でした。
- コンバージョン率の相対差異は 10% でした。これは、Optimizely では改善と呼ばれます。
差の区間では、10% ではなく 1% を含む範囲が表示されます。
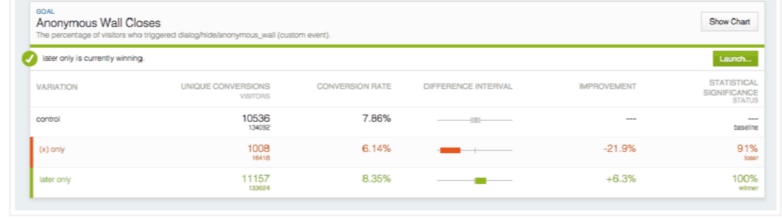
例:「優勢な」区間

この例では、下のバリエーションに表示された改善が偶然によるものではない可能性 が 97% であると言うことができます。ただし、Optimizely で測定された改善(+15.6%)が、現在確認されている正確な改善ではない可能性があります。
実際には、オリジナルではなくバリエーションを実装した場合、コンバージョン率の差は、基準コンバージョン率を 0.29% から 4.33% 上回る可能性があります。そのため、14.81% の基準コンバージョン率と比較すると、バリエーションのコンバージョ ン率は 15.1%(14.81 + 0.29)から 19.14%(14.81 + 4.33)の範囲であることがわかります。
統計的有意性が 97% でも、実際の結果が差の区間の範囲に収まる可能性はまだ 90%あります。これは、プロジェクトの統計的有意性の設定が 90% に設定されているた めです。つまり、差の区間の可能性は、バリエーションの観測統計的有意性が変わっても変わりません。通常は、Optimizely で収集されるデータが多いほど、範囲は狭くなります。
この実験では、オリジナル(14.81%)とバリエーション(17.12%)の間で観測される差異が 2.31 %であり、これは差異区間内に含まれます。この実験を再実行するときに、ベースラインとバリエーションのコンバージョン率の差異が同じ範囲内にあることが確認される可能性が高くなります。
例:「劣勢な」区間
もう 1 つの例では、差異区間が完全に 0 を下回っています。

この例では、下のバリエーションに表示されたマイナスの改善が偶然によるものではない可能性が 91% であると言うことができます。ただし、Optimizely で測定された改善(-21.9%)が、必ずしも現在確認されているものではない可能性があります。
実際には、オリジナルではなくバリエーションを実装した場合、コンバージョン率の 差は基準コンバージョン率を -2.41% から -1.03% 下回る可能性があります。そのた め、7.86% の基準コンバージョン率と比較すると、バリエーションのコンバージョン 率は 5.45%(7.86 - 2.41)から 6.83%(7.86 - 1.03)の範囲であることがわかります。
この実験では、オリジナル(7.86%)とバリエーション(6.14%)の間で観測される 差異が -1.72%であり、これは差異区間内に含まれます。この実験を再実行するときに、ベースラインとバリエーションのコンバージョン率の差異が同じ範囲内にあることが確認される可能性が高くなります
例:不確定な区間
早い段階でテストを停止する必要がある場合、またはサンプルサイズが小さい場合は、そのバリエーションの実装が優勢または劣勢のいずれの影響をもたらすかを差異区間から(大まかに)把握できます。
このため、特定の目標での統計的有意性が低い場合は、意思決定のためのもう 1 つの データポイントとして差異区間を使用できます。不確定な目標がある場合、区間は次のようになります。

ここでは、このバリエーションのコンバージョン率の差は -0.58% から 3.78% の間になる、つまりプラスになる可能性もマイナスになる可能性もあると言うことができます。Optimizely ではまだわかりません。
このバリエーションを実装するときに確実に言えることは、「最悪で 0.58% 低下、最良で 3.78% 向上という、信頼性が 21% のテスト結果を実装しました」となります。これにより、そのバリエーションを実装する価値があるかどうかについて、ビジネス上の意思決定を行うことができます。
統計的有意性と差の区間との関係
上記で説明したとおり、実際の結果が差の区間の範囲に収まる可能性は 90% あります。これは、プロジェクトの統計的有意性の設定が 90% に設定されているためです。実際のコンバージョン率の差が、差の区間の範囲内に収まることをより強く確信したい場合は、統計的有意性の設定を開始して、差の区間をより広くします。統計的有意性の設定のレベルを高くすると、これに対応して差の区間も広くなり、実際の結果が区間に収まる可能性も高くなります。逆もまた同様です。
実際には、さらに深い関係が進行しています。実際の結果が差の区間内に収まる可能性は 90% なので、収まらない可能性は 10% あります。そのため、差の区間が完全に 0 の右または左にある場合、実際のコンバージョン率の差が 0 である可能性は最大10% あることがわかります。実際のコンバージョン率の差が 0 ではないことは少なくとも 90% 確信しており、これは、観測した内容が偶然によるものではないことを意味します。しかし、これは統計的有意性についてこれまで説明してきたとおりのことなのです。
結論として、成功と失敗の分け方および信頼区間の幅は、統計的有意性の設定で管理されます。差の区間が完全に 0 の右(または左)になったそのときに、成功(または失敗)と見なされます。
推定待ち時間と 0% の有意性
テストの実行中に、Optimizely では、テストが結論に達するまでにかかる推定待ち時間も算出されます。これはベースラインとバリエーションのコンバージョン率が現在観測されている値と変わらないことを前提として算出されます。これは、平均または予期される待ち時間ですが、個々の結果は異なる可能性があります。
![[改善] 列に表示される有意性](https://optimizely.gaprise.jp/hubfs/Imported_Blog_Media/original-Feb-23-2022-08-23-57-32-AM.png)
結果を確認すると、[改善] 列に大きな割合が示されていますが、有意性が 0% であ り、一定数の「残り訪問者数」があることが確認できます。次に例を示します。
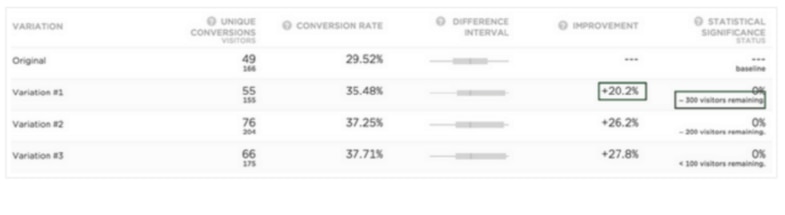
ここでは、20.2% の改善が見られますが、統計的有意性は 0%、残り訪問者数は 300です。
なぜこれが表示されるのでしょうか。左側では、[ユニークコンバージョン] の下に、当該バリエーションの訪問者数が 155 だけであることが示されています。統計学的には、このテストは「検出力が低い」と言います。155 件の訪問者では、観測される効果がオリジナルとバリエーションの実際の違いによるものか、単なる偶然であるかを判断する十分な証拠を Optimizely に提供できないためです。訪問者の数が、有意な結果を得るために必要な合計訪問者数の 40% または 50% に達すると、統計的有意性が増加し始めます。
Optimizely がこのバリエーションのコンバージョン率とオリジナルのコンバージョン率の差異について判断するには、そのバリエーションに対してさらに 300 以上の訪問者がアクセスする必要があります。
サンプルサイズの重要性の詳細については、テストの実行期間に関する記事を参照してください。
ヒント:
サンプルサイズカリキュレーターはどうなったのでしょうか?以前、Optimizely では、テスト開始前にサンプルサイズと検出可能な最小の影響を設定する必要がありました(多くのテストツールでサポートされている統計では依然として そのようになっています)。統計エンジンでは、前もって大きなサンプルサイズを設定す る作業を行う必要がなくなり、より多くのテストを実行できるようになりました。
ただし、多くのテストプログラムでは、前もってテストの実行期間を推定することが重要です。統計エンジンをベースに新しいサンプルサイズカリキュレーターを開発しました。このカリキュレーターでは、テストの実行にかかる平均時間を推定できます。このカリキ ュレーターを使用し、待機可能な最長時間を表す MDE を選択することをお勧めします。 実験で大きな改善を見込めない場合には、テストを早めに停止できます。
ビジネス上の意思決定のための統計エンジンの解釈
統計エンジンは、結果をいつでも、だれでも可能な限り容易に解釈できるようにすることを目標にしています。結果ページを開き、目標の [統計的有意性] 列を確認するだけで解釈できます。
この数値が必要な有意水準(デフォルトでは 90%)を超えている場合は、バリエーションによる改善が良好であるかまたは不良であるかに基づき、勝者または敗者を決定できます。
統計エンジンでは、実験の実行中はいつでも正確な統計的有意性が表示されるので、有意水準が高いかまたは低いかに応じて結果に基づく意思決定を行うことができます。
Optimizely のデフォルト有意水準は 90% ですが、これは、頻度、トラフィックレベル、リスク許容度によっては、すべての組織にとって適切であるわけではありません。お客様が各自のビジネスニーズに対応した統計標準を用いて実験を実行することをお勧めします。結果に基づいてビジネス上の意思決定を行う際に、各自の有意水準を考慮してください。
たとえば、トラフィックレベルが低い場合は、より多くの実験を実行できるように、 80% の統計的有意性でテストを実行することが適切である場合があります。
時間の経過に伴う統計的有意性の向上
Optimizely の統計エンジンでは、他のプラットフォームで見られる固定型の水平テストの代わりに、順次テストが使用されている点に注意してください。つまり、時間の経過に伴って統計的有意性が変動するのではなく、時間の経過に伴い、Optimizely により証拠が収集され、統計的有意性が上昇します。証拠が強力になるにつれ、統計的有意性が徐々に上昇します。
Optimizely では、時間の経過に伴い主に 2 種類の確実な証拠が収集されます。
- コンバージョン率の大きな差異
- 訪問者の増加に伴い一貫したコンバージョン率の差異
この証拠のウェイトは、どの時点であるかによって異なります。実験の早期段階において、サンプルサイズが小さい時点でのコンバージョン率の大きな差異は、実験で訪問者数が増加した時点よりも控えめに扱われます。この時点で [統計的有意性] の線が横ばい状態になり始め、その後 Optimizely が証拠の収集を開始すると急激に上昇します。
適切な管理下にある環境では、統計的有意性が常時段階的に上昇することが期待されます。統計的有意性が急激に上昇する場合は、テストで以前よりも多くの確実な証拠が累積していることを意味します。反対に、横ばい状態の期間においては、統計エンジンは、テストについてすでに判明しているもの以外の確実な証拠を検出していません。
以下に、Optimizely が時間の経過に伴って証拠を収集し、結果ページに表示する様子を示します。赤色の円で囲まれている部分は、実験の早期の段階で発生するとされる「横ばい」の線です。
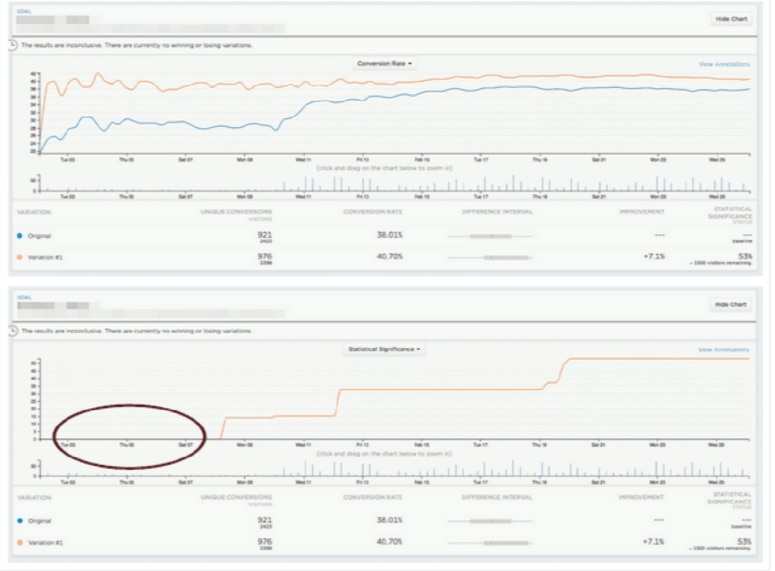
統計的有意性が、受容可能な統計的有意性しきい値(デフォルトでは 90%)を超えたら、改善の方向に基づいて勝者または敗者を宣言します。段階的な上昇については、 コミュニティでの段階的な上昇に関する解説を参照してください。
外部イベントによる訂正
適切な管理下にある環境では、統計エンジンによる統計的有意性の計算は常に増加します。ただし実際の実験は適切な管理下にある環境で行われず、さまざまな要因によ って実験中間部が変化する可能性があります。Optimizely の分析では、このような状況が発生することは稀です(テストの 4% 未満)。
この状況が発生した場合、統計エンジンは再較正中であることを通知し、統計的有意性の計算を低下させる可能性があります。統計的有意性が低下する場合、これはOptimizely が、証拠が次の 2 つの可能性のいずれかを支持するうえで十分であると判断したためです。
- 有意に見える一連のデータがあるが、それが有意ではないと見なせるだけの十分な追加情報が収集された。
- 環境で根本的な変化が生じたため、より控えめに計算する必要がある。
- 実験の実行中にトラフィックの割り当てを変更した(これが原因で、結果の精度に問題が生じる可能性がある)。
OPTIMIZELY での収益の処理
簡潔に言えば、統計エンジンは、訪問者に対する収益の目標については意図したとおりに機能します。いつでも結果を確認し、勝者と敗者の誤差率や、訪問者に対する収益(RPV)の差異区間を正確に評価することができます。
バリエーションとベースラインの間の平均収益の差異を求めるテストは、コンバージョン率の差異を求めるテストよりも困難です。これは、収益分布が右裾に大きく偏る (歪む)傾向にあるためです。この歪みにより、t 検定と統計エンジンを含む多くの手法が依存する分布結果が妨げられます。これは実質的に、平均収益の差異が実際に存在する場合に、これらの手法ではその差異を検出できる能力が低いことを意味します。
Optimizely の統計エンジンでは、歪度修正と呼ばれる手法により、収益または収益に関連する常に重要な目標をテストする際にこの低下した能力を一部回復できます。歪度修正は、統計エンジンのその他の機能と適切に連携するように明示的に設計されています。
これは、主に次の 2 通りの方法で影響します。
- Optimizely の A/B テストで一般に示される訪問者数のタイプに対しては、平均収益の差異の検出の方がより合理的です。
- 常に重要な目標の信頼区間は、現在観測される効果量に関して対称的ではなくなります。分布の根本的な歪度が、信頼区間の形状に正しく反映されるようになりました。
OPTIMIZELY では片側検定と両側検定のどちらが使用されますか?
検定(テスト)を実行するときには、片側検定または両側検定を実行できます。両側検定は、オリジナルとバリエーションの両方向の差異を検出するように設計されており、バリエーションが勝者と敗者のいずれであるかを示します。片側検定は、オリジナルとバリエーションの片方向の差異を検出するように設計されています。
Optimizely では、以前は片側検定を使用していました。Optimizely 統計エンジンの導入に伴い、両側検定に切り替えられました。これは、Optimizely 統計エンジンに実装された偽陽性率制御に両側検定が必要であるためです。
実際には、ビジネス上の意思決定の能力にとっては、片側検定と両側検定のいずれを使用するかよりも、偽陽性率制御の方が重要です。これは、ビジネス上の意思決定においては、偽陽性または偽陰性を取り込まないようにすることが主要な目標であるためです。偽陽性または偽陰性が発生するかどうかよりも、誤った結果が発生する実際の確率を把握し、複数の目標を追加したことで結果が低下することがないようにしておくほうが大事です。
実装
ホームページの [設定] タブで、特定のプロジェクトのすべての設定を管理できます。
このセクションでは、このセクションでは、[実装] サブタブで使用できる設定を説明します。
![.[設定] タブで特定のプロジェクトのすべての設定を管理](https://optimizely.gaprise.jp/hubfs/Imported_Blog_Media/original-Feb-23-2022-08-23-59-74-AM.png)
- [JavaScript] サブタブが見つかりませんか?プロジェクトの [設定]の下に[JavaScript] があります。
- [プライバシー] サブタブが見つかりませんか?プロジェクトの [設定] の下に[プライバシー] (英語だけ) があります。
[設定] 内の [実装] サブタブでは、Optimizely スニペット(ウェブプロジェクトの場合)またはSDK のインストール手順(モバイルプロジェクトの場合)と、プロジェクト ID を確認できます。
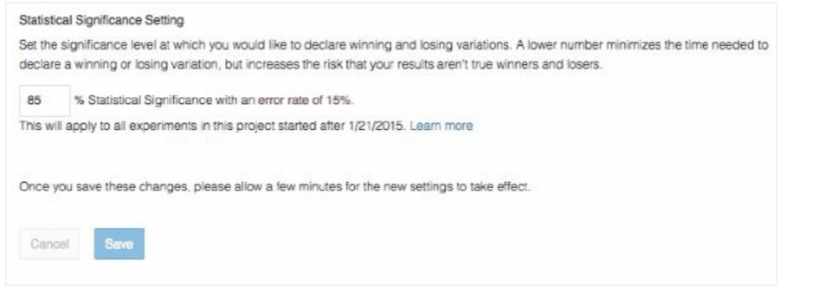
統計的有意性の設定
実験を実行すると、Optimizely の統計エンジンは常に結果を分析して、結果が有意かどうか、つまり、表示されている結果に、単なる雑音や偶然性ではなく訪問者の行動の変化が実際にどの程度確実に反映されているかを判断します。
統計的有意性の設定により、Optimizely が結果ページで有意な結果(勝者と敗者)を宣言するプロジェクト全体の有意水準を設定できます。[実装] サブタブの Optimizelyスニペットまたは SDK インストール手順の下に、[統計的有意性の設定] があります。
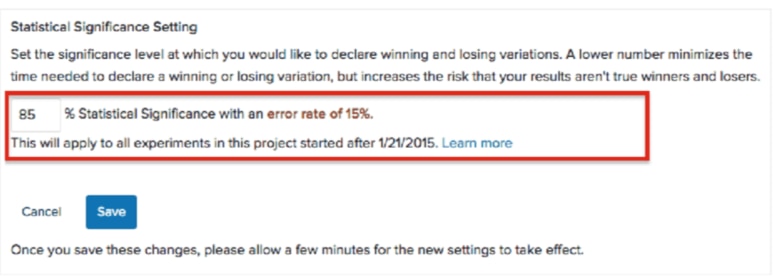
この数が組織のリスク許容度(統計用語では、1 - [p 値])に一致するとします。90%の有意したい値を設定すると、Optimizely は、統計的に有意な結果があると 90% 確信した場合に結果を宣言します。これは、エラー率が 10% であることが予想されることも意味します。
統計的有意性の設定を変更する際には必ず、特定のトレードオフを考慮する必要があります。一般的には、有意設定が高いほどより正確になり、より大きいサンプルサイズが必要になるため、Optimizely が有意な結果を宣言するのにかかる時間が長くなります。有意水準が低いほど、有意な結果の宣言に必要な時間が短くなりますが、この設定を小さくすると、それらの結果の一部が誤検知となる可能性も高くなります。
注:
有意性の設定を変更すると、現在実行中のすべての実験に即座に影響します。そのため、実験の統計的に有意な勝者の目標が 85% だった場合に、統計的有意性の設定を 90% から 80% に変更すると、次に結果ページをロードしたときには成功と して表示されます(85% > 80%)。このような信頼の必要性の減少を反映して、差の区間も適宜に縮小されます。
Related Articles
